6a Applying Machine Learning
Aug 13, 2017 14:06 · 634 words · 3 minutes read
Deciding what to try next
Errors in your predictions can be troubleshooted by:
- Getting more training examples
- Trying smaller sets of features
- Trying additional features
- Trying polynomial features
- Increasing or decreasing $\lambda$
Rather than picking one of these avenues at random, there are diagnostic techniques for choosing one of these solutions.
Evaluating a Hypothesis
Test Set error
A hypothesis may have low error for training examples, but still be inaccurate due to overfitting.
We can split the data into two sets: a training set and a test set. Then:
- Learn $\Theta$ and minimise $J_{train} ( \Theta )$ using the training set
- Compute the test set error $J_{test} ( \Theta )$
For linear regression, $J_{test}$ is the usual average squared error, and for logistic regression it's roughly the proportion of data that was misclassified.
Model Selection and Train/Validation/Test Sets
If you're using the Test Set technique and want to pick a polynomial degree $d$, you might optimise $\Theta$ using the training set for each polynomial degree, then find the degree with the least error using the test set.
However is means that we've trained the classifier using the test set, which will skew the error!
To get around this, we introduce the Cross Validation Set that we can train $d$ with. Normally the split is 60% Training, 20% Cross Validation, 20% Test Set.
Diagnosing Bias vs Variance
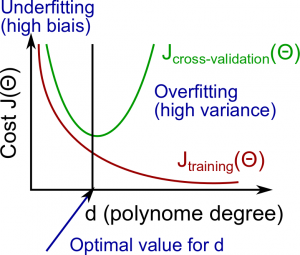
There's a relationship between the degree of the polynomial $d$ and the underfitting (high bias) or overfitting (high variance) of our hypothesis.
The training error will tend to decrease as we increase $d$. At the same time the cross-validation error will tend to decrease up to a point, and then it will increase, forming a convex curve.
High bias (underfitting): both $J_{train} ( \Theta )$ and $J_{CV} ( \Theta )$ will be high. Also, $J_{CV} ( \Theta ) \approx J_{train} ( \Theta )$
High variance (overfitting): $J_{train} ( \Theta )$ will be low, and $J_{CV} ( \Theta ) \gg J_{train} ( \Theta )$
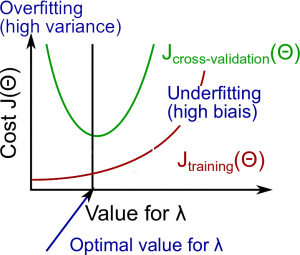
Regularisation and Bias/Variance
Looking at regularisation parameter $\lambda$.
- Large $\lambda$: High bias (underfitting)
- Intermediate $\lambda$: just right
- Small $\lambda$: high variance (overfitting)
A large lambda heavily penalises all the $\Theta$ parameters, which greatly simplifies the function so causes underfitting.
The relationship of $\lambda$ to the training set and cross validation set is:
- Low $\lambda$: $J_{train} (\Theta)$ is low and $J_{CV} (\Theta)$ is high (high variance/overfitting)
- Intermediate $\lambda$: $J_{train} (\Theta)$ and $J_{CV} (\Theta)$ are somewhat low, and $J_{train} (\Theta) \approx J_{CV} (\Theta)$
- Large $\lambda$: $J_{train} (\Theta)$ and $J_{CV} (\Theta)$ will be high (underfitting/high bias)
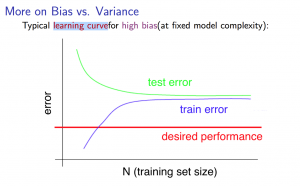
Training set size
With high bias:
- Low training set size: causes $J_{train} (\Theta)$ to be low and $J_{CV} (\Theta)$ to be high
- Large training set size: causes both $J_{train} (\Theta)$ and $J_{CV} (\Theta)$ to be high with $J_{train} (\Theta) \approx J_{CV} (\Theta)$
If an algorithm is suffering from high bias, more training data will not (by itself) help much.
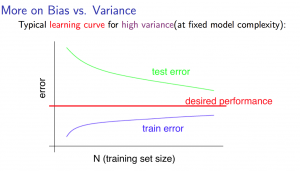
With high variance
- Low training set size: $J_{train} (\Theta)$ will be low, and $J_{CV} (\Theta)$ will be high
- Large training set size: $J_{train} (\Theta)$ increases with training set size, and $J_{CV} (\Theta)$ continues to decrease without levelling off. Also $J_{train} (\Theta) \lt J_{CV} (\Theta)$ but the difference between them remains significant.
If an algorithm is suffering from high variance, getting more training data is likely to help.
Deciding what to do next
- High variance:
- Get more training examples
- Smaller set of features
- Increasing $\lambda$
- High bias:
- Add features
- Add polynomial features
- Decreasing $\lambda$
Neural Networks
A network with fewer parameters is prone to underfitting. It's also computationally cheaper.
A large neural network with more parameters is prone to overfitting. It's more computationally expensive. Can use regularisation to address overfitting.
Using a single hidden layer is a good starting default. Can use the cross validation set to train on the number of hidden layers.